The data - the analysis and methodology are below!
New Evaluation Methods
This is the first of a series of articles looking into the results of the new, open-source translation comparison benchmark. Unlike the old benchmark, accuracy and idiomaticity have been merged into a single judgement from 0-100. However, there are lots of improvements, including the ability to filter by evaluating model and sentence type, as well as P-values (just click on a row!).
Testing Coherence
The old coherence metric (tl;dr: translate from English to German and back multiple times and compare how close each iteration is to the original) was a useful way to sidestep LLM bias. I ran some of the top models through the coherence metric in order to sanity-check the results:
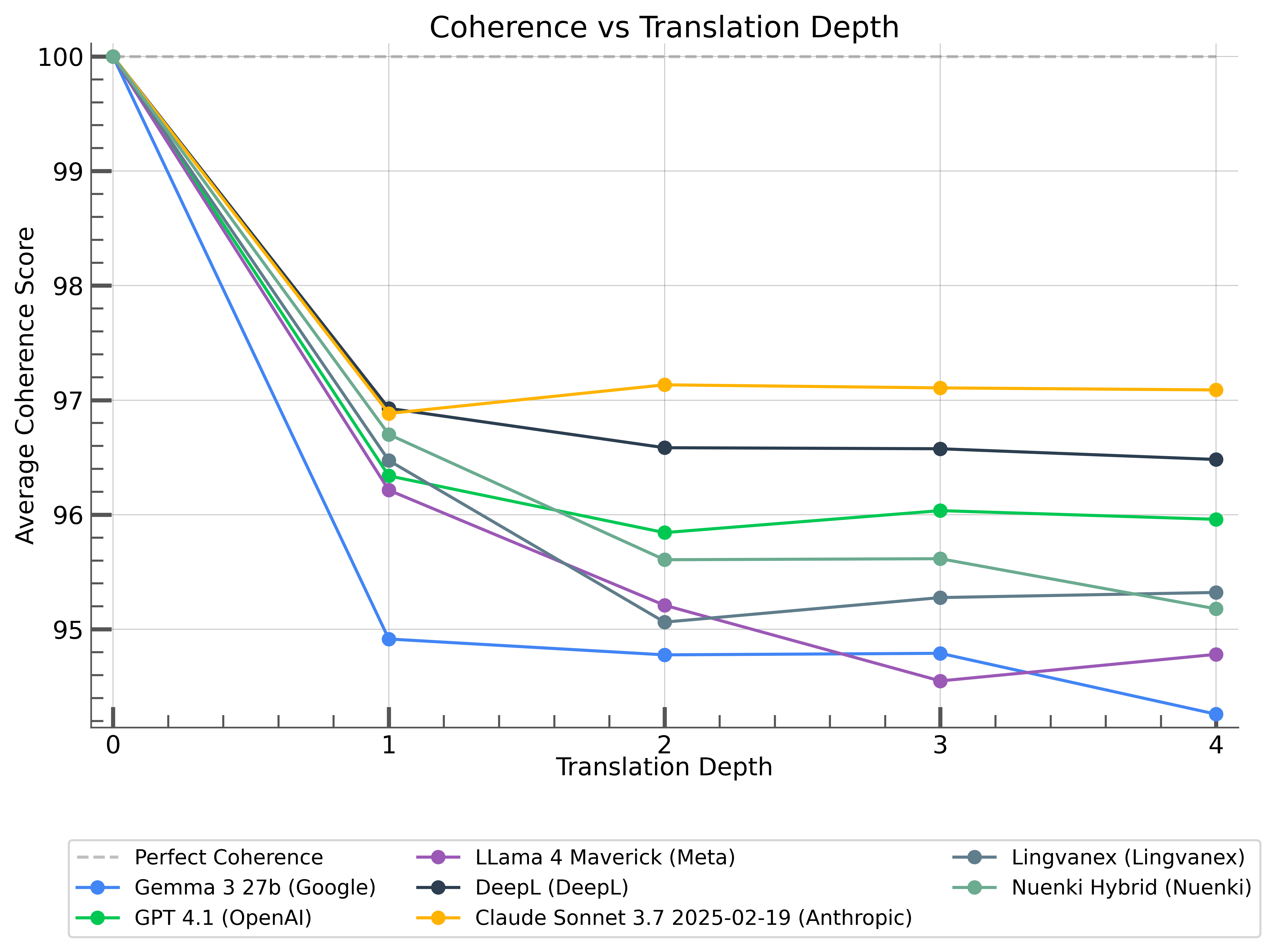
You can see that Claude and DeepL do quite well, with Llama 4 Maverick exhibiting a clear decrease at each stage. DeepL's coherence matches up with previous findings that showed that small, literal, translation-tuned models did better at accuracy and coherence but worse at idiomaticity, while larger models were less coherent but produced more idiomatic translations.
I'm not sure why Claude is doing so well, but it's quite impressive! It's worth noting that Sonnet being slightly behind GPT-4.1 etc has quite poor P-values, so it may well be slightly better than the data below would indicate at first glance.
Some of the preliminary tests I did clearly indicated that lower temperatures fared better, so I've switched Nuenki Hybrid from t=0.7 to t=0.1. The data in this benchmark is entirely from the old version.
Another interesting result is that Gemini 2.5 Flash Preview does better with thinking off than on (p=0.055). I'm going to do more in depth tests of that in the future! I also forgot to include Deepseek V3; I'll include that in future benchmarks.
The new data has some models that weren't in the old benchmark, and it's indicating that it'd be a good idea to switch Nuenki to Llama 4 Maverick via Groq for low-latency translation, and add Gemini 2.5 Flash Preview non-thinking and Qwen 3 235B A22B to the hybrid translator.
Anyway - I'll leave you to the data!