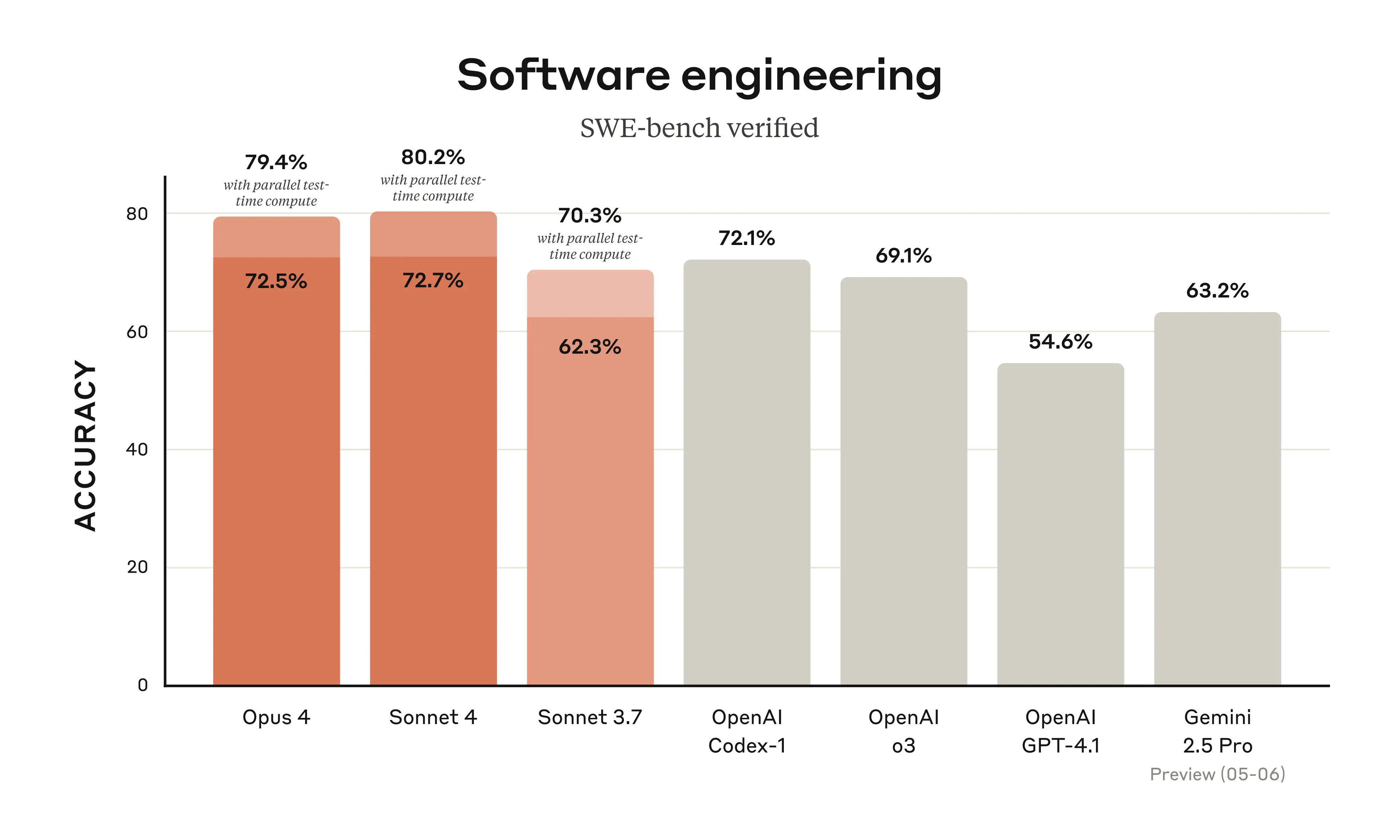
Claude 4 released a few days ago, and it performs well at software engineering.
Anthropic's models have previously been quite good at translation, often outperforming their contemporary peers. At the same time, Anthropic has had a noticeable shift as they focus more and more on programming performance over other metrics. Their blog post has a noticeable focus on AI agents and programming over other fields. I decided to add Sonnet 4 and Opus 4 to the translation benchmark in order to see how they performed.
The results (raw data below) are somewhat disappointing. The two models are at the top of the leaderboard, among peers that are difficult to statistically differentiate (you can click an entry to see its P-values). Opus has no clear improvement over Sonnet, with Sonnet being slightly higher in the combined leaderboard (p=0.487). They aren't even clearly better than Deepseek V3 (p=0.114), and they're worse than GPT-4o.
Nuenki's open source Hybrid Translator continues to beat everything else (p < 0.001) by combining multiple translations and using the translation-evaluation asymmetry (models are better at critiquing translations than making them themselves) to produce better results. There's a demo here, if you'd like to give it a try!
This benchmark is also open source.